Hardware counters provided by the Intel performance monitoring unit (PMU) are a great way to obtain metrics such as L1/2/3 cache misses, instructions executed, etc at fine-grained resolution. While there are a number of tools such as linux-perf, VTune, etc. for obtaining said metrics, my (admittedly non-exhaustive) search concluded that there was no good way to obtain hardware metrics for a sub-section of code, as shown below:
int main() {
/***************************************
* Initialize array with random numbers *
****************************************/
int n = 1000000;
long* arr = (long*)malloc(sizeof(long)*n);
for (int i=0; i<n; i+=1) {
arr[i] = random();
}
/*************************
*** Code to benchmark ****
**************************/
sort(arr, n);
/*************************/
return 0;
}Suppose we only want to benchmark the section of code for sorting while omitting the overhead of initializing the array, I found it difficult to use existing tools in such cases without imposing additional overhead.
This is where the facilities provided by the Intel PMU come in handy.
That being said, Intel's Developer Manual which details how to use the PMU is not the easiest document to decipher. The information pertinent to using the PMU is scattered in multiple places in the manual and the internet. I've put together the relevant information I found in this blogpost.
The Basics
Registers are the interface to the PMU.
How to program MSRs?
node:~> sudo apt install msr-tools
node:~> sudo wrmsr 0x186 0x43412e
node:~> sudo rdmsr 0x186
43412e
How to read performance counters?
unsigned long rdpmc_l3_cache_misses() {
unsigned long a, d, c;
c = 0;
__asm__ __volatile__("rdpmc" : "=a" (a), "=d" (d) : "c" (c));
return ((unsigned long)a) | (((unsigned long)d) << 32);
}...
unsigned long l3_misses = rdpmc_l3_cache_misses();
<...
code to benchmark
...>
l3_misses = rdpmc_l3_cache_misses() - l3_misses;
...Exploring the PMU's capabilities
cpuid is a useful tool to explore the hardware's capabilities. The 0x0AH leaf gives information about the PMU.
node:~> sudo apt install cpuid
node:~> cpuid -1 -l 0x0ah
CPU:
Architecture Performance Monitoring Features (0xa/eax):
version ID = 0x4 (4)
number of counters per logical processor = 0x4 (4)
bit width of counter = 0x30 (48)
length of EBX bit vector = 0x7 (7)
Architecture Performance Monitoring Features (0xa/ebx):
core cycle event not available = false
instruction retired event not available = false
reference cycles event not available = false
last-level cache ref event not available = false
last-level cache miss event not avail = false
branch inst retired event not available = false
branch mispred retired event not avail = false
Architecture Performance Monitoring Features (0xa/edx):
number of fixed counters = 0x3 (3)
bit width of fixed counters = 0x30 (48)
Intel CPUs have different architecture families, such as Skylake, Kaby Lake, etc. For instance, the Intel Xeon Silver 4114 10-core CPU belongs to the Skylake architecture family:
node:~> cat /sys/devices/cpu/caps/pmu_name
skylake
There are three types of performance events supported by the PMU:
- Fixed counters: The cpuid 0x0AH leaf shows that the version ID of the PMU is 4, and there are three fixed counters supported by PMU. These counters are retired instructions, core cycles, and TSC reference cycles (Table 18-2 in the manual). These three are commonly used performance events and hence incorporated as fixed counters. All PMUs with version ID 2 and higher support these fixed counters, which includes processors since Intel Core 2 Duo T 7700 released in 2007.
- Architectural performance events: Aside from the fixed counters, the PMU provides limited MSRs to program performance events of choice. The cpuid leaf shows that there are four counters per logical processor. These MSRs are named IA32_PERFEVTSELx, where x ranges from 0-3 in our case. Some processors can provide up to 8 counters, but the register address of these counters is fixed starting from 0x186 for MSR IA32_PERFEVTSEL0 for all Intel architectures. Architectural performance events have the same event code independent of the PMU architecture family. There are seven such events highlighted in green (Table 18-1 in the manual) typically supported by all Intel PMUs. Note that the first three architectural events are the same as fixed counters.
- Non-architectural performance events: Some less frequently used performance events such as L2 and L1 cache misses can be specific to the PMU's architecture family. Programming the MSRs for these events requires looking up the manual for specifications of that particular architecture family.
Enabling the PMU
The PMU is disabled by default, and can be turned on by programming the global performance control register IA32_PERF_GLOBAL_CTRL at address 0x38f. The format of the register is shown below (Figure 18-3 from the manual):

node:~> sudo wrmsr 0x38f 0x70000000f
Instead, if the CPU had 8 available counters, we would set the lower 8 bits.
node:~> sudo wrmsr 0x38f 0x7000000ff
Enabling Fixed Counters
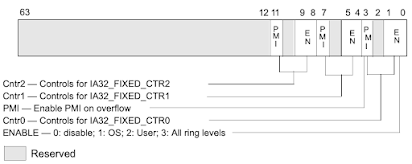
Note that we have not set the overflow control (bit 3), as we are not handling this corner case. For information on how to detect and handle overflow, refer to section 18.2.2 in the manual.
// Total number of instructions executed (retired)
unsigned long rdpmc_retired_inst() {
unsigned long a, d, c;
c = (1<<30);
__asm__ __volatile__("rdpmc" : "=a" (a), "=d" (d) : "c" (c));
return ((unsigned long)a) | (((unsigned long)d) << 32);
}
// Total number of core cycles. Note that when CPU frequency
// scaling is enabled (default), time elapsed does not scale
// linearly with core cycles.
unsigned long rdpmc_core_cycles() {
unsigned long a, d, c;
c = (1<<30) + 1;
__asm__ __volatile__("rdpmc" : "=a" (a), "=d" (d) : "c" (c));
return ((unsigned long)a) | (((unsigned long)d) << 32);
}
// Reference cycles at the rate of the system's time stamp counter (TSC).
// This metric is unaffected by CPU frequency scaling.
unsigned long rdpmc_tsc_reference_cyles() {
unsigned long a, d, c;
c = (1<<30) + 2;
__asm__ __volatile__("rdpmc" : "=a" (a), "=d" (d) : "c" (c));
return ((unsigned long)a) | (((unsigned long)d) << 32);
}Programming performance events

unsigned long rdpmc_l3_cache_refs() {
unsigned long a, d, c;
c = 1;
__asm__ __volatile__("rdpmc" : "=a" (a), "=d" (d) : "c" (c));
return ((unsigned long)a) | (((unsigned long)d) << 32);
}unsigned long rdpmc_l2_cache_miss() {
unsigned long a, d, c;
c = 2;
__asm__ __volatile__("rdpmc" : "=a" (a), "=d" (d) : "c" (c));
return ((unsigned long)a) | (((unsigned long)d) << 32);
}
No comments:
Post a Comment